Mit der Version 2.0 der SAP-HANA-Datenbank ist noch ein nützlicher Operator in SQLScript für deklarativen Code hinzugekommen: MAP_MERGE. Mit ihm lässt sich das gelegentlich vorkommende Problem lösen, dass für alle N Zeilen einer Tabelle eine Tabellenfunktion ausgeführt werden soll. Die N Ergebnistabellen sollen dann per UNION zusammengefasst werden. Der MAP_MERGE-Operator kann diese Aufgabe parallelisieren.
Ohne MAP_MERGE benötigt man imperatives Coding mit einer Schleife über der Tabelle. Durch den Operator kann man diese sequenzielle Verarbeitung vermeiden. Das Beispiel in Listing 1.52 zeigt die Verwendung des Operators. Hier wird für eine Menge von Tabellennamen die Anzahl der Datensätze ermittelt. Das entsprechende dynamische SQL (Siehe auch 6.7, Dynamisches SQL ausführen) für den Tabellennamen wird in der Tabellenfunktion MAP_TABLE_ROW_COUNT erzeugt und ausgeführt.
--Anlegen der MAP-Funktion
CREATE FUNCTION map_table_row_count(IN iv_tabname nvarchar(30))
RETURNS TABLE (tabname NVARCHAR(30),
rowcount INT )
AS BEGIN
DECLARE lv_sql NVARCHAR(100);
DECLARE lt_result TABLE( tabname NVARCHAR(30),
rowcount INT );
EXEC 'SELECT '''
|| :iv_tabname
|| ''' AS tabname, '
|| 'COUNT(*) as rowcount '
|| 'FROM '
|| :iv_tabname
INTO lt_result;
RETURN SELECT * FROM :lt_result;
END;
--Aufruf des MAP_MERGE Operators in einem Anonymen Block
DO BEGIN
lt_table = SELECT left(table_name,30) AS tabname
FROM m_cs_tables
WHERE schema_name = 'SYSTEM';
lt_result = MAP_MERGE( :lt_table,
map_table_row_count(
:lt_table.tabname) );
SELECT * FROM :lt_result;
END;
Listing: Verwendung des MAP_MERGE Operators
In dem anonymen Block werden alle Tabellennamen aus dem Schema SYSTEM ausgelesen. Damit werden dann mit dem MAP_MERGE Operator und der Tabellenfunktion MAP_TABLE_ROW_COUNT die Einträge gezählt. Das Ergebnis können Sie in der folgenden Abbildung sehen.
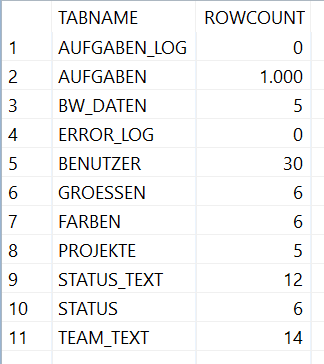
Abbildung: Ergebnis des Listings
Sowohl MAP_MERGE als auch MAP_REDUCE gehören zum Bereich der deklarativen Programmierung. Sie bieten sich vor allem dann an, wenn ansonsten Prozeduren oder Funktionen in einer Schleife aufgerufen werden müssten. Das ist insbesondere deshalb vorteilhaft, weil die MAP und REDUCE Funktionen häufig imperative Logik enthalten, die somit parallel ausgeführt werden kann.